# NeuroDB 2.0 说明文档
# 简介
NeuroDB 是一个内存级图数据库引擎,能够利用 Neuro-Cypher 指令实现对图数据的创建、编辑、检索以及建立在复杂图算法上的一些高级图应用。
# 2.0 版本新特性
相比 1.0 版本,NeuroDB 2.0 在以下方面进行了重大升级:
- 主从复制集群:采用状态机驱动的全量+增量复制机制,支持一主多从架构,实现数据高可用与读写分离
- 工业级 Cypher 解析器:采用 Flex/Bison 重构词法/语法解析器,解析速度提升 2-3 倍,错误定位精确到字符级别,代码可维护性和扩展性大幅提升
- 正则表达式支持:
=~操作符全面支持标准正则表达式(^、$、*、+、?、\d、\w、字符类等),可进行邮箱、电话、身份证、URL 等复杂格式匹配 - 快速 CSV 导入:新增
LOAD CSV FROM ... NODES和LOAD CSV FROM ... RELATIONSHIPS高速批量导入命令,大幅提升数据导入效率
# 核心特性
NeuroDB 的主要特性为:
- 轻量级:整个引擎的可执行程序仅有不到 400KB
- 内存级:整个图数据被完全载入到内存中进行操作
- 高速:得益于整个数据库都在内存中,无硬盘读写延迟;2.0 采用 Flex/Bison 解析器进一步加速查询解析
- 可嵌入式:数据库可以嵌入到您项目里类似 SQLite,无需单独部署运维
- 多平台:各主流操作系统(Windows、Linux、Mac)以及手机操作系统(Android、iPhone)和任何可运行 C 语言目标程序的嵌入式系统或单片机(STM32)都可运行 NeuroDB
- 精简化:精简的操控指令、精简的部署运维、精简的软件架构实现强大、高效、低资源消耗的图数据库引擎
- 全自主研发:提供图数据库国产替代方案
- 边缘计算:得益于 NeuroDB 的轻量级,其可嵌入到小型、微型设备上(芯片上)实现"边缘计算"
- 集群化(2.0 新增):支持主从复制,一主多从实现读写分离与数据高可用
- 图建模概念:NeuroDB 的可视化客户端实现了类似面向对象根据模型"派生"图数据的概念,可在建模中设计图的节点、关系关联结构,并且可以向关系数据库表结构那样设计节点或关系上的属性(属性名、属性数据类型、属性数据长度等)
本教程将以极简的风格,教会您在 1 小时内学会 NeuroDB 的所有技术!Here we go!
# 下载安装部署
# 下载程序包部署
安装部署前我们需要到 下载页面 (opens new window),下载您系统对应的版本的 NeuroDB 程序包。安装部署工作非常简单,只需要把下载的 NeuroDB 程序包解压到您习惯放软件的目录即可。
# Docker 部署
docker pull panggguoming/neurodb:2.0.0
# 程序包目录
程序包目录如下:

其中:
- bin 目录下是 NeuroDB 服务端与客户端可执行程序
- data 目录下是持久化存储的数据文件
- import 目录下是待导入的数据文件(CSV 文件)
- logs 目录下是运行日志
部署完毕后:
- 启动 bin 目录下的 NEURO_SERVER 即可将 NeuroDB 服务启动,默认占用 8839 端口,如果想更换接口可以在后续"运维管理"章节讲如何修改。
- 启动 bin 目录下的 NEURO_CLI 可以启动命令行客户端,此客户端默认链接本机 8839 端口,可通过添加参数
host 127.0.0.1 port 8839修改默认链接 IP 和端口,我们可以直接在客户端输入命令并查看执行结果。 - 为了更形象、便捷的运行指令和查看结果,推荐下载安装 NeuroStudio (opens new window) 桌面版可视化客户端,"NeuroStudio"提供强大、友好的可视化 UI 组件提升我们操作图数据、展示图数据的体验,本教程中后续的实例将使用 NeuroStudio 截图展示结果。其安装、运行非常简单,下载解压后运行根目录下的"neuro-Studio.exe"即可。NeuroStudio 是可选安装包,如果用户只需要运行指令无需可视化展示,则不必下载安装"NeuroStudio"。
# 启动 NeuroDB
# Windows 系统
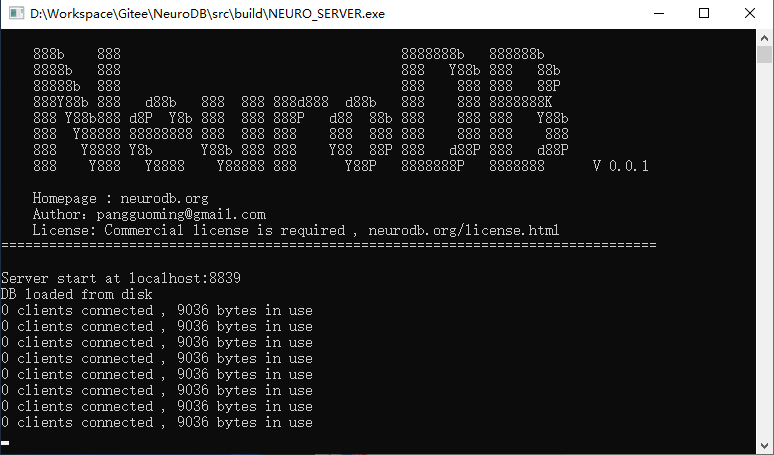
将程序包解压到任意目录,运行 bin 目录下的 NEURO_SERVER.exe,这是 NeuroDB 的服务端。也可以在命令行下运行。
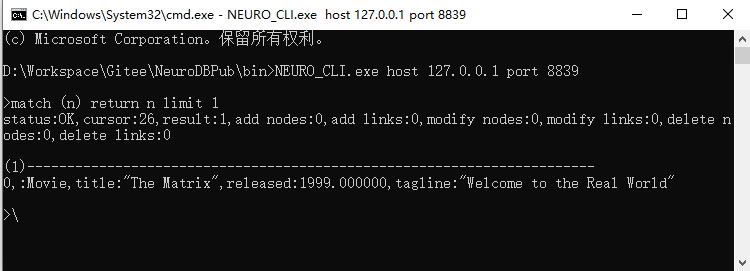
命令行客户端是 NEURO_CLI.exe,服务端启动后再启动此程序即可,如需输入参数连接指定 IP 和端口的服务,则需在命令行中输入如下命令来启动。NEURO_CLI 启动后在命令行中我们可以直接输入 Neuro-Cypher 命令执行并查看命令行结果。
# Linux 系统
将程序包解压到任意目录,赋予 bin 目录下的 NEURO_SERVER 可执行权限:
chmod +x NEURO_SERVER
运行 NEURO_SERVER 即可:
./NEURO_SERVER
或者可以使用 nohup 命令使之在后台运行:
nohup ./NEURO_SERVER &
然后启动客户端,就可以连接到服务端并执行命令了:
./NEURO_CLI
# Mac 系统
将程序包解压到任意目录,运行 bin 目录下的 NEURO_SERVER 即可:
./NEURO_SERVER
然后启动客户端,就可以连接到服务端并执行命令了:
./NEURO_CLI
# 快速上手
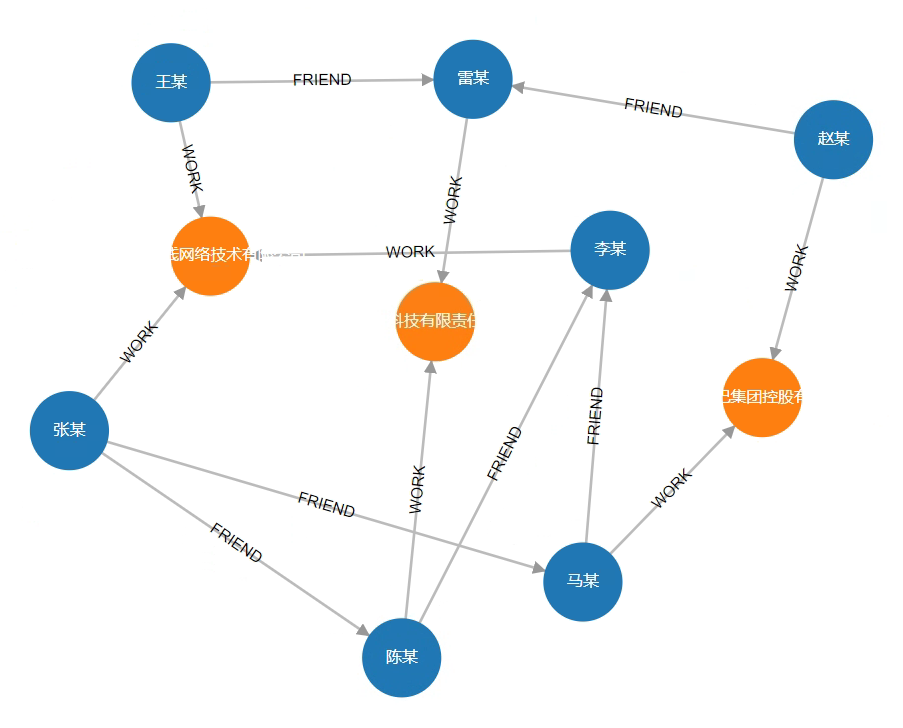
# 创建人脉关系图实例
创建公司(Company)、人员(Person)节点,以及公司与人员的工作关系(WORK),人员之间的朋友关系(FRIEND),从而构建一个简单的人脉关系网络。
CREATE
(Xiaomi:Company {name:"小米科技有限责任公司", create_at:2010, tagline:"致力于让全球每个人都能享受科技带来的美好生活"})
, (Alibaba:Company {name:"阿里巴巴集团控股有限公司", create_at:1999, tagline:"旨在构建未来的商业基础设施"})
, (Baidu:Company {name:"百度在线网络技术有限公司", create_at:2000, tagline:"是拥有强大互联网基础的领先AI公司"})
, (Leimou:Person {name:"雷某", born:1969})
, (Mamou:Person {name:"马某", born:1964})
, (Limou:Person {name:"李某", born:1968})
, (Chenmou:Person {name:"陈某", born:1960})
, (Zhangmou:Person {name:"张某", born:1967})
, (Wangmou:Person {name:"王某", born:1965})
, (Zhaomou:Person {name:"赵某", born:1952})
, (Leimou)-[:WORK {position:"CEO"}]->(Xiaomi)
, (Chenmou)-[:WORK {position:"员工"}]->(Xiaomi)
, (Mamou)-[:WORK {position:"CEO"}]->(Alibaba)
, (Zhaomou)-[:WORK {position:"员工"}]->(Alibaba)
, (Limou)-[:WORK {position:"CEO"}]->(Baidu)
, (Wangmou)-[:WORK {position:"员工"}]->(Baidu)
, (Zhangmou)-[:WORK {position:"员工"}]->(Baidu)
, (Wangmou)-[:FRIEND{weight:2}]->(Leimou)
, (Zhaomou)-[:FRIEND{weight:1}]->(Leimou)
, (Zhangmou)-[:FRIEND{weight:4}]->(Mamou)
, (Zhangmou)-[:FRIEND{weight:8}]->(Chenmou)
, (Chenmou)-[:FRIEND{weight:5}]->(Limou)
, (Mamou)-[:FRIEND{weight:10}]->(Limou)
创建完毕后,可视化效果如下:
# 检索
# 1. 查询名叫"王某"的人员
MATCH (n:Person{name:"王某"}) RETURN n
结果:
status:OK,cursor:40,result:1,add nodes:0,add links:0,modify nodes:0,modify links:0,delete nodes:0,delete links:0
(1)-----------------------------------------------------------------------
ID:8 LABELS:Person PROPS:{name:"王某",born:1965.000000}
# 2. 查询 1965 年后出生的人员
MATCH (n:Person) WHERE n.born > 1965 RETURN n
结果:
status:OK,cursor:45,result:3,add nodes:0,add links:0,modify nodes:0,modify links:0,delete nodes:0,delete links:0
(1)-----------------------------------------------------------------------
ID:3 LABELS:Person PROPS:{name:"雷某",born:1969.000000}
(2)-----------------------------------------------------------------------
ID:5 LABELS:Person PROPS:{name:"李某",born:1968.000000}
(3)-----------------------------------------------------------------------
ID:7 LABELS:Person PROPS:{name:"张某",born:1967.000000}
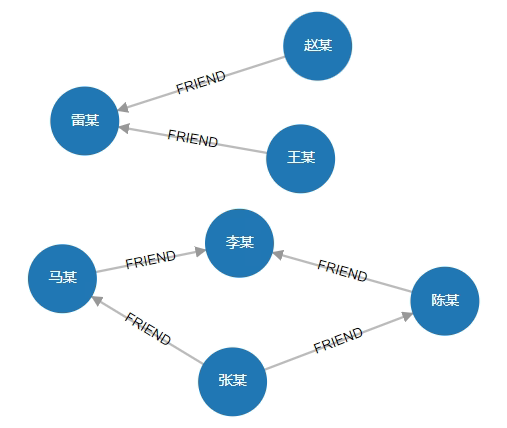
# 3. 查询所有的"朋友"关系
MATCH (n)-[r:FRIEND]->(m) RETURN n,r,m
结果:
status:OK,cursor:38,result:6,add nodes:0,add links:0,modify nodes:0,modify links:0,delete nodes:0,delete links:0
(1)-----------------------------------------------------------------------
ID:4 LABELS:Person PROPS:{name:"马某",born:1964.000000} ID:12 HEAD:4 TAIL:5 TYPE:FRIEND PROPS:{weight:10} ID:5 LABELS:Person PROPS:{name:"李某",born:1968.000000}
(2)-----------------------------------------------------------------------
ID:6 LABELS:Person PROPS:{name:"陈某",born:1960.000000} ID:11 HEAD:6 TAIL:5 TYPE:FRIEND PROPS:{weight:5} ID:5 LABELS:Person PROPS:{name:"李某",born:1968.000000}
(3)-----------------------------------------------------------------------
ID:7 LABELS:Person PROPS:{name:"张某",born:1967.000000} ID:10 HEAD:7 TAIL:6 TYPE:FRIEND PROPS:{weight:8} ID:6 LABELS:Person PROPS:{name:"陈某",born:1960.000000}
(4)-----------------------------------------------------------------------
ID:7 LABELS:Person PROPS:{name:"张某",born:1967.000000} ID:9 HEAD:7 TAIL:4 TYPE:FRIEND PROPS:{weight:4} ID:4 LABELS:Person PROPS:{name:"马某",born:1964.000000}
(5)-----------------------------------------------------------------------
ID:8 LABELS:Person PROPS:{name:"王某",born:1965.000000} ID:7 HEAD:8 TAIL:3 TYPE:FRIEND PROPS:{weight:2} ID:3 LABELS:Person PROPS:{name:"雷某",born:1969.000000}
(6)-----------------------------------------------------------------------
ID:9 LABELS:Person PROPS:{name:"赵某",born:1952.000000} ID:8 HEAD:9 TAIL:3 TYPE:FRIEND PROPS:{weight:1} ID:3 LABELS:Person PROPS:{name:"雷某",born:1969.000000}
可视化:
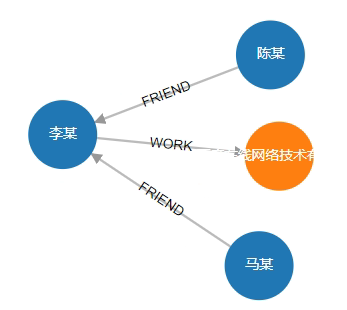
# 4. 查询与人员"李某"相关联的所有"一度"关系
MATCH (n:Person{name:"李某"})-[r]-(m) RETURN n,r,m
结果:
status:OK,cursor:52,result:3,add nodes:0,add links:0,modify nodes:0,modify links:0,delete nodes:0,delete links:0
(1)-----------------------------------------------------------------------
ID:5 LABELS:Person PROPS:{name:"李某",born:1968.000000} ID:4 HEAD:5 TAIL:2 TYPE:WORK PROPS:{position:"CEO"} ID:2 LABELS:Company PROPS:{name:"百度在线网络技术有限公司",create_at:2000.000000,tagline:"是拥有强大互联网基础的领先AI公司"}
(2)-----------------------------------------------------------------------
ID:5 LABELS:Person PROPS:{name:"李某",born:1968.000000} ID:12 HEAD:4 TAIL:5 TYPE:FRIEND PROPS:{weight:10} ID:4 LABELS:Person PROPS:{name:"马某",born:1964.000000}
(3)-----------------------------------------------------------------------
ID:5 LABELS:Person PROPS:{name:"李某",born:1968.000000} ID:11 HEAD:6 TAIL:5 TYPE:FRIEND PROPS:{weight:5} ID:6 LABELS:Person PROPS:{name:"陈某",born:1960.000000}
可视化:
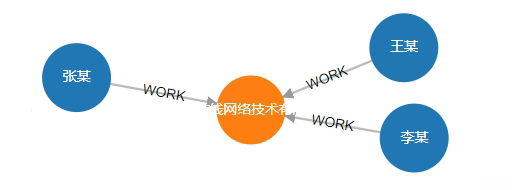
# 5. 找到"张某"工作的公司以及他所有同事
MATCH (n:Person{name:"张某"})-[w1:WORK]-> (c:Company) <-[w2:WORK]-(n2) RETURN n,w1,c,w2,n2
结果:
status:OK,cursor:93,result:2,add nodes:0,add links:0,modify nodes:0,modify links:0,delete nodes:0,delete links:0
(1)-----------------------------------------------------------------------
ID:7 LABELS:Person PROPS:{name:"张某",born:1967.000000} ID:6 HEAD:7 TAIL:2 TYPE:WORK PROPS:{} ID:2 LABELS:Company PROPS:{name:"百度在线网络技术有限公司",create_at:2000.000000,tagline:"是拥有强大互联网基础的领先AI公司"} ID:5 HEAD:8 TAIL:2 TYPE:WORK PROPS:{position:"员工"} ID:8 LABELS:Person PROPS:{name:"王某",born:1965.000000}
(2)-----------------------------------------------------------------------
ID:7 LABELS:Person PROPS:{name:"张某",born:1967.000000} ID:6 HEAD:7 TAIL:2 TYPE:WORK PROPS:{} ID:2 LABELS:Company PROPS:{name:"百度在线网络技术有限公司",create_at:2000.000000,tagline:"是拥有强大互联网基础的领先AI公司"} ID:4 HEAD:5 TAIL:2 TYPE:WORK PROPS:{position:"CEO"} ID:5 LABELS:Person PROPS:{name:"李某",born:1968.000000}
可视化:
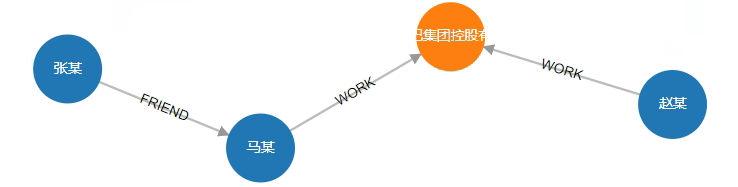
# 6. 查询"张某"与"赵某"的最短人脉路径
通过下面结果可知张某与马某是朋友,而马某与赵某是同一个公司的同事。
MATCH path=(start :Person{name:"张某"})-[rels *<]- (end :Person{name:"赵某"}) RETURN path
结果:
status:OK,cursor:95,result:1,add nodes:0,add links:0,modify nodes:0,modify links:0,delete nodes:0,delete links:0
(1)-----------------------------------------------------------------------
ID:7 LABELS:Person PROPS:{name:"张某",born:1967.000000} ID:9 HEAD:7 TAIL:4 TYPE:FRIEND PROPS:{weight:4} ID:4 LABELS:Person PROPS:{name:"马某",born:1964.000000} ID:2 HEAD:4 TAIL:1 TYPE:WORK PROPS:{position:"CEO"} ID:1 LABELS:Company PROPS:{name:"阿里巴巴集团控股有限公司",create_at:1999.000000,tagline:"旨在构建未来的商业基础设施"} ID:3 HEAD:9 TAIL:1 TYPE:WORK PROPS:{position:"员工"} ID:9 LABELS:Person PROPS:{name:"赵某",born:1952.000000}
可视化:
# 修改
# 1. 为人员"张某"添加性别属性
MATCH (n :Person{name:"张某"}) SET n.sex="男" RETURN n
# 2. 为人员"张某"修改性别属性为女
MATCH (n :Person{name:"张某"}) SET n.sex="女" RETURN n
# 删除
删除操作要注意,如果某个节点带有任何关系边,则无法直接删除,需要先删除其所有关系边后才可以删除此节点,或者我们可以用 DETACH DELETE 指令一步到位一条指令同时删除其关联的所有关系边和此节点。
# 1. 删除张某与马某的朋友关系
MATCH (n :Person{name:"张某"})-[r:FRIEND]->(m :Person{name:"马某"}) DELETE r
# 2. 删除人员张某节点
此命令会提示无法删除,因为张某还有两条关联关系没删除,只有用上述指令删除此节点的所有关联关系后,本指令才会运行成功。
MATCH (n :Person{name:"张某"}) DELETE n
# 3. 一次性删除人员张某节点及其关联的所有关系
此指令不会出现无法删除的情况,因为它是一条指令同时删除所有关联关系然后再删除此节点。
MATCH (n :Person{name:"张某"}) DETACH DELETE n
# 总结
至此,我们就快速的上手体验了 NeuroDB 的一个人脉关系实例,实例的数据量非常小,但这便于我们运行和理解,实际应用中,NeuroDB 支持海量数据构成的图。
# Neuro-Cypher 指令
Neuro-Cypher 是一种声明式图数据库查询语言,它具有丰富的表现力,能高效地查询和更新图数据。
2.0 解析器升级:NeuroDB 2.0 采用 Flex/Bison 构建的工业级词法/语法解析器,替代了 1.0 的手写解析器。新解析器解析速度提升 2-3 倍,错误定位精确到字符级别,代码可维护性和语法扩展性分别提升 5 倍和 10 倍。编译依赖 Flex >= 2.5 和 Bison >= 3.0,用户使用层面完全兼容 1.0 语法。
# 图数据结构
图由节点和关系构成。节点可能还带有标签和属性,关系带有类型和属性。节点表达的是实体,关系连接一对节点。节点可以看作类似关系数据库中的表,但又不完全一样。节点的标签可以理解为不同的表名,属性类似关系数据库中表的列。一个节点的数据类似关系数据库中表的一行数据。拥有相同标签的节点通常具有类似的属性。
# 模式(Pattern)
我们可以通过模式将复杂的想法编码为众多节点和关系,Neuro-Cypher 查询语言很依赖于描述模式。模式可以简单到只有一对节点以及连接这对节点的关系。例如,一个人住(LIVES_IN)在某个城市或者某个城市属于(PART_OF)某个国家。模式也可以复杂到使用多个关系来表达复杂的概念,从而可以支持各种有趣的使用场景。例如,下面的 Cypher 代码将两个简单的模式连接在一起:
(:Person) -[:WORK]-> (:Company)
# 描述节点
Cypher 采用一对圆括号来表示节点,如:()、(foo)。下面是一些常见的节点表示法:
() -- 空节点
(xiaomi) -- 只有节点变量名的空节点
(:Company) -- 有节点标签定义的节点
(xiaomi:Company) -- 有变量名和标签定义的节点
(xiaomi:Company {name: "xiaomi"}) -- 有变量名、标签和一个 name 属性的节点
(xiaomi:Company {name: "xiaomi", create_at: 1997}) -- 有变量名、标签和两个属性的节点
# 描述关系
Cypher 使用一对短横线(即 --)表示一个无方向关系。有方向的关系则在其中一端加上一个箭头(即 <-- 或 -->)。方括号表达式 […] 可用于添加详情。里面可以包含变量、属性和(或者)类型信息。关系的常见表达方式如下:
--> -- 空关系
-[role]-> -- 只有一个变量名的空关系
-[:WORK]-> -- 带有关系类型的关系
-[role:WORK]-> -- 带有变量名和关系类型的关系
-[role:WORK {position: "CEO"}]-> -- 带有变量名、类型、一个属性的关系
# 模式语法
可以将以上节点和关系的语法组合在一起来表达模式。下面是一个简单的模式:
(leimou:Person {name:"雷某", born:1969})-[:WORK {position:"CEO"}]->
(Xiaomi:Company {name:"小米科技有限责任公司", create_at:2010, tagline:"致力于让全球每个人都能享受科技带来的美好生活"})
# 数据类型
Cypher 支持以下数据类型:
属性类型:
- 数字(Integer)
- 浮点数(Double)
- 字符串(String)
- 布尔值(Boolean)
- 数字数组(Integer Array)
- 字符串数组(String Array)
结构类型:
- 节点(Node)
- 关系(Relationship)
- 路径(Path)
# MATCH 指令
MATCH 语句用指定的模式(Pattern)来检索数据库。它常与带有约束或者断言的 WHERE 语句一起使用。
# 查找节点
1. 查询所有节点
模式中只有一个变量其他无任何限定条件,则返回全部节点:
MATCH (n) RETURN n
结果:
status:OK,cursor:18,result:10,add nodes:0,add links:0,modify nodes:0,modify links:0,delete nodes:0,delete links:0
(1)-----------------------------------------------------------------------
ID:0 LABELS:Company PROPS:{name:"小米科技有限责任公司",create_at:2010.000000,tagline:"致力于让全球每个人都能享受科技带来的美好生活"}
(2)-----------------------------------------------------------------------
ID:1 LABELS:Company PROPS:{name:"阿里巴巴集团控股有限公司",create_at:1999.000000,tagline:"旨在构建未来的商业基础设施"}
(3)-----------------------------------------------------------------------
ID:2 LABELS:Company PROPS:{name:"百度在线网络技术有限公司",create_at:2000.000000,tagline:"是拥有强大互联网基础的领先AI公司"}
(4)-----------------------------------------------------------------------
ID:3 LABELS:Person PROPS:{name:"雷某",born:1969.000000}
(5)-----------------------------------------------------------------------
ID:4 LABELS:Person PROPS:{name:"马某",born:1964.000000}
(6)-----------------------------------------------------------------------
ID:5 LABELS:Person PROPS:{name:"李某",born:1968.000000}
(7)-----------------------------------------------------------------------
ID:6 LABELS:Person PROPS:{name:"陈某",born:1960.000000}
(8)-----------------------------------------------------------------------
ID:7 LABELS:Person PROPS:{name:"张某",born:1967.000000}
(9)-----------------------------------------------------------------------
ID:8 LABELS:Person PROPS:{name:"王某",born:1965.000000}
(10)-----------------------------------------------------------------------
ID:9 LABELS:Person PROPS:{name:"赵某",born:1952.000000}
2. 查询带有某个标签的所有节点
在模式中节点上添加 :Company 标签:
MATCH (n:Company) RETURN n
结果:
status:OK,cursor:26,result:3,add nodes:0,add links:0,modify nodes:0,modify links:0,delete nodes:0,delete links:0
(1)-----------------------------------------------------------------------
ID:0 LABELS:Company PROPS:{name:"小米科技有限责任公司",create_at:2010.000000,tagline:"致力于让全球每个人都能享受科技带来的美好生活"}
(2)-----------------------------------------------------------------------
ID:1 LABELS:Company PROPS:{name:"阿里巴巴集团控股有限公司",create_at:1999.000000,tagline:"旨在构建未来的商业基础设施"}
(3)-----------------------------------------------------------------------
ID:2 LABELS:Company PROPS:{name:"百度在线网络技术有限公司",create_at:2000.000000,tagline:"是拥有强大互联网基础的领先AI公司"}
3. 查询 ID 为 0 的节点
MATCH (n #0) RETURN n
结果:
status:OK,cursor:21,result:1,add nodes:0,add links:0,modify nodes:0,modify links:0,delete nodes:0,delete links:0
(1)-----------------------------------------------------------------------
ID:0 LABELS:Company PROPS:{name:"小米科技有限责任公司",create_at:2010.000000,tagline:"致力于让全球每个人都能享受科技带来的美好生活"}
# 查找关系
1. 按方向查找关系
关系的方向可以通过 --> 或者 <-- 来表示。如匹配人员节点"王某"向外指出的所有关系:
MATCH (:Person { name:"王某" })-->(m) RETURN m
反之,想要匹配指向王某的所有关系:
MATCH (:Person { name:"王某" })<--(m) RETURN m
因为以上两条指令关系上无任何限定条件,所以会查出指出和指向王某的所有关系。
2. 为关系添加变量,并返回关系
MATCH (:Person { name:"王某" })-[r]->() RETURN r
结果:
status:OK,cursor:48,result:3,add nodes:0,add links:0,modify nodes:0,modify links:0,delete nodes:0,delete links:0
(1)-----------------------------------------------------------------------
ID:10 HEAD:7 TAIL:6 TYPE:FRIEND PROPS:{weight:8}
(2)-----------------------------------------------------------------------
ID:9 HEAD:7 TAIL:4 TYPE:FRIEND PROPS:{weight:4}
(3)-----------------------------------------------------------------------
ID:6 HEAD:7 TAIL:2 TYPE:WORK PROPS:{}
3. 查找 ID 为 0 的关系
MATCH ()-[r #0]->() RETURN r
结果:
status:OK,cursor:28,result:1,add nodes:0,add links:0,modify nodes:0,modify links:0,delete nodes:0,delete links:0
(1)-----------------------------------------------------------------------
ID:0 HEAD:3 TAIL:0 TYPE:WORK PROPS:{position:"CEO"}
4. 匹配关系类型:查询所有的"朋友"关系
MATCH (n)-[r:FRIEND]->(m) RETURN n,r,m
结果:
status:OK,cursor:38,result:6,add nodes:0,add links:0,modify nodes:0,modify links:0,delete nodes:0,delete links:0
(1)-----------------------------------------------------------------------
ID:4 LABELS:Person PROPS:{name:"马某",born:1964.000000} ID:12 HEAD:4 TAIL:5 TYPE:FRIEND PROPS:{weight:10} ID:5 LABELS:Person PROPS:{name:"李某",born:1968.000000}
(2)-----------------------------------------------------------------------
ID:6 LABELS:Person PROPS:{name:"陈某",born:1960.000000} ID:11 HEAD:6 TAIL:5 TYPE:FRIEND PROPS:{weight:5} ID:5 LABELS:Person PROPS:{name:"李某",born:1968.000000}
(3)-----------------------------------------------------------------------
ID:7 LABELS:Person PROPS:{name:"张某",born:1967.000000} ID:10 HEAD:7 TAIL:6 TYPE:FRIEND PROPS:{weight:8} ID:6 LABELS:Person PROPS:{name:"陈某",born:1960.000000}
(4)-----------------------------------------------------------------------
ID:7 LABELS:Person PROPS:{name:"张某",born:1967.000000} ID:9 HEAD:7 TAIL:4 TYPE:FRIEND PROPS:{weight:4} ID:4 LABELS:Person PROPS:{name:"马某",born:1964.000000}
(5)-----------------------------------------------------------------------
ID:8 LABELS:Person PROPS:{name:"王某",born:1965.000000} ID:7 HEAD:8 TAIL:3 TYPE:FRIEND PROPS:{weight:2} ID:3 LABELS:Person PROPS:{name:"雷某",born:1969.000000}
(6)-----------------------------------------------------------------------
ID:9 LABELS:Person PROPS:{name:"赵某",born:1952.000000} ID:8 HEAD:9 TAIL:3 TYPE:FRIEND PROPS:{weight:1} ID:3 LABELS:Person PROPS:{name:"雷某",born:1969.000000}
5. 匹配多种关系类型:查找 FRIEND 或 WORK 类型的关系
MATCH ()-[r:FRIEND|WORK]->() RETURN r
结果:
status:OK,cursor:37,result:13,add nodes:0,add links:0,modify nodes:0,modify links:0,delete nodes:0,delete links:0
(1)-----------------------------------------------------------------------
ID:0 HEAD:3 TAIL:0 TYPE:WORK PROPS:{position:"CEO"}
(2)-----------------------------------------------------------------------
ID:12 HEAD:4 TAIL:5 TYPE:FRIEND PROPS:{weight:10}
(3)-----------------------------------------------------------------------
ID:2 HEAD:4 TAIL:1 TYPE:WORK PROPS:{position:"CEO"}
(4)-----------------------------------------------------------------------
ID:4 HEAD:5 TAIL:2 TYPE:WORK PROPS:{position:"CEO"}
(5)-----------------------------------------------------------------------
ID:11 HEAD:6 TAIL:5 TYPE:FRIEND PROPS:{weight:5}
(6)-----------------------------------------------------------------------
ID:1 HEAD:6 TAIL:0 TYPE:WORK PROPS:{position:"员工"}
(7)-----------------------------------------------------------------------
ID:10 HEAD:7 TAIL:6 TYPE:FRIEND PROPS:{weight:8}
(8)-----------------------------------------------------------------------
ID:9 HEAD:7 TAIL:4 TYPE:FRIEND PROPS:{weight:4}
(9)-----------------------------------------------------------------------
ID:6 HEAD:7 TAIL:2 TYPE:WORK PROPS:{}
(10)-----------------------------------------------------------------------
ID:7 HEAD:8 TAIL:3 TYPE:FRIEND PROPS:{weight:2}
(11)-----------------------------------------------------------------------
ID:5 HEAD:8 TAIL:2 TYPE:WORK PROPS:{position:"员工"}
(12)-----------------------------------------------------------------------
ID:8 HEAD:9 TAIL:3 TYPE:FRIEND PROPS:{}
(13)-----------------------------------------------------------------------
ID:3 HEAD:9 TAIL:1 TYPE:WORK PROPS:{position:"员工"}
6. 查找关系上带有属性 "position" 为 "CEO" 的关系
MATCH ()-[r {position:"CEO"}]->() RETURN r
结果:
status:OK,cursor:42,result:3,add nodes:0,add links:0,modify nodes:0,modify links:0,delete nodes:0,delete links:0
(1)-----------------------------------------------------------------------
ID:0 HEAD:3 TAIL:0 TYPE:WORK PROPS:{position:"CEO"}
(2)-----------------------------------------------------------------------
ID:2 HEAD:4 TAIL:1 TYPE:WORK PROPS:{position:"CEO"}
(3)-----------------------------------------------------------------------
ID:4 HEAD:5 TAIL:2 TYPE:WORK PROPS:{position:"CEO"}
7. 查找多条关系组合的模式
也就是指定关系的长度,如查找两条关系与三个节点组合的模式,我们称之为长度为 2 的模式:
MATCH (n1)-[r1]->(n2)-[r2]->(n3) RETURN n1,r1,n2,r2,n3
结果:
status:OK,cursor:54,result:8,add nodes:0,add links:0,modify nodes:0,modify links:0,delete nodes:0,delete links:0
(1)-----------------------------------------------------------------------
ID:4 LABELS:Person PROPS:{name:"马某",born:1964.000000} ID:12 HEAD:4 TAIL:5 TYPE:FRIEND PROPS:{weight:10} ID:5 LABELS:Person PROPS:{name:"李某",born:1968.000000} ID:4 HEAD:5 TAIL:2 TYPE:WORK PROPS:{position:"CEO"} ID:2 LABELS:Company PROPS:{name:"百度在线网络技术有限公司",create_at:2000.000000,tagline:"是拥有强大互联网基础的领先AI公司"}
(2)-----------------------------------------------------------------------
ID:6 LABELS:Person PROPS:{name:"陈某",born:1960.000000} ID:11 HEAD:6 TAIL:5 TYPE:FRIEND PROPS:{weight:5} ID:5 LABELS:Person PROPS:{name:"李某",born:1968.000000} ID:4 HEAD:5 TAIL:2 TYPE:WORK PROPS:{position:"CEO"} ID:2 LABELS:Company PROPS:{name:"百度在线网络技术有限公司",create_at:2000.000000,tagline:"是拥有强大互联网基础的领先AI公司"}
(3)-----------------------------------------------------------------------
ID:7 LABELS:Person PROPS:{name:"张某",born:1967.000000} ID:10 HEAD:7 TAIL:6 TYPE:FRIEND PROPS:{weight:8} ID:6 LABELS:Person PROPS:{name:"陈某",born:1960.000000} ID:11 HEAD:6 TAIL:5 TYPE:FRIEND PROPS:{weight:5} ID:5 LABELS:Person PROPS:{name:"李某",born:1968.000000}
(4)-----------------------------------------------------------------------
ID:7 LABELS:Person PROPS:{name:"张某",born:1967.000000} ID:10 HEAD:7 TAIL:6 TYPE:FRIEND PROPS:{weight:8} ID:6 LABELS:Person PROPS:{name:"陈某",born:1960.000000} ID:1 HEAD:6 TAIL:0 TYPE:WORK PROPS:{position:"员工"} ID:0 LABELS:Company PROPS:{name:"小米科技有限责任公司",create_at:2010.000000,tagline:"致力于让全球每个人都能享受科技带来的美好生活"}
(5)-----------------------------------------------------------------------
ID:7 LABELS:Person PROPS:{name:"张某",born:1967.000000} ID:9 HEAD:7 TAIL:4 TYPE:FRIEND PROPS:{weight:4} ID:4 LABELS:Person PROPS:{name:"马某",born:1964.000000} ID:12 HEAD:4 TAIL:5 TYPE:FRIEND PROPS:{weight:10} ID:5 LABELS:Person PROPS:{name:"李某",born:1968.000000}
(6)-----------------------------------------------------------------------
ID:7 LABELS:Person PROPS:{name:"张某",born:1967.000000} ID:9 HEAD:7 TAIL:4 TYPE:FRIEND PROPS:{weight:4} ID:4 LABELS:Person PROPS:{name:"马某",born:1964.000000} ID:2 HEAD:4 TAIL:1 TYPE:WORK PROPS:{position:"CEO"} ID:1 LABELS:Company PROPS:{name:"阿里巴巴集团控股有限公司",create_at:1999.000000,tagline:"旨在构建未来的商业基础设施"}
(7)-----------------------------------------------------------------------
ID:8 LABELS:Person PROPS:{name:"王某",born:1965.000000} ID:7 HEAD:8 TAIL:3 TYPE:FRIEND PROPS:{weight:2} ID:3 LABELS:Person PROPS:{name:"雷某",born:1969.000000} ID:0 HEAD:3 TAIL:0 TYPE:WORK PROPS:{position:"CEO"} ID:0 LABELS:Company PROPS:{name:"小米科技有限责任公司",create_at:2010.000000,tagline:"致力于让全球每个人都能享受科技带来的美好生活"}
(8)-----------------------------------------------------------------------
ID:9 LABELS:Person PROPS:{name:"赵某",born:1952.000000} ID:8 HEAD:9 TAIL:3 TYPE:FRIEND PROPS:{} ID:3 LABELS:Person PROPS:{name:"雷某",born:1969.000000} ID:0 HEAD:3 TAIL:0 TYPE:WORK PROPS:{position:"CEO"} ID:0 LABELS:Company PROPS:{name:"小米科技有限责任公司",create_at:2010.000000,tagline:"致力于让全球每个人都能享受科技带来的美好生活"}
# 查找路径
1. 查找可变长度的路径
查找关系长度最小为 2 的模式,即长度大于等于 2 的所有关系及其首尾节点:
MATCH (n1:Person{name:"王某"})-[r*2..]->(n2) RETURN n1,r,n2
结果:
status:OK,cursor:61,result:1,add nodes:0,add links:0,modify nodes:0,modify links:0,delete nodes:0,delete links:0
(1)-----------------------------------------------------------------------
ID:8 LABELS:Person PROPS:{name:"王某",born:1965.000000} ID:7 HEAD:8 TAIL:3 TYPE:FRIEND PROPS:{weight:2} ID:0 HEAD:3 TAIL:0 TYPE:WORK PROPS:{position:"CEO"} ID:0 LABELS:Company PROPS:{name:"小米科技有限责任公司",create_at:2010.000000,tagline:"致力于让全球每个人都能享受科技带来的美好生活"}
2. 查找关系长度最大为 2 的模式
即长度为 1 和长度为 2 的关系及其首尾节点:
MATCH (n1:Person{name:"王某"})-[r*..2]->(n2) RETURN n1,r,n2
结果:
status:OK,cursor:61,result:3,add nodes:0,add links:0,modify nodes:0,modify links:0,delete nodes:0,delete links:0
(1)-----------------------------------------------------------------------
ID:8 LABELS:Person PROPS:{name:"王某",born:1965.000000} ID:7 HEAD:8 TAIL:3 TYPE:FRIEND PROPS:{weight:2} ID:0 HEAD:3 TAIL:0 TYPE:WORK PROPS:{position:"CEO"} ID:0 LABELS:Company PROPS:{name:"小米科技有限责任公司",create_at:2010.000000,tagline:"致力于让全球每个人都能享受科技带来的美好生活"}
(2)-----------------------------------------------------------------------
ID:8 LABELS:Person PROPS:{name:"王某",born:1965.000000} ID:5 HEAD:8 TAIL:2 TYPE:WORK PROPS:{position:"员工"} ID:2 LABELS:Company PROPS:{name:"百度在线网络技术有限公司",create_at:2000.000000,tagline:"是拥有强大互联网基础的领先AI公司"}
(3)-----------------------------------------------------------------------
ID:8 LABELS:Person PROPS:{name:"王某",born:1965.000000} ID:7 HEAD:8 TAIL:3 TYPE:FRIEND PROPS:{weight:2} ID:3 LABELS:Person PROPS:{name:"雷某",born:1969.000000}
3. 查找指定长度指定为 3 的所有关系及其首尾节点
MATCH (n1)-[r*3..3]->(n2) RETURN n1,r,n2
结果:
status:OK,cursor:40,result:2,add nodes:0,add links:0,modify nodes:0,modify links:0,delete nodes:0,delete links:0
(1)-----------------------------------------------------------------------
ID:7 LABELS:Person PROPS:{name:"张某",born:1967.000000} ID:10 HEAD:7 TAIL:6 TYPE:FRIEND PROPS:{weight:8} ID:11 HEAD:6 TAIL:5 TYPE:FRIEND PROPS:{weight:5} ID:4 HEAD:5 TAIL:2 TYPE:WORK PROPS:{position:"CEO"} ID:2 LABELS:Company PROPS:{name:"百度在线网络技术有限公司",create_at:2000.000000,tagline:"是拥有强大互联网基础的领先AI公司"}
(2)-----------------------------------------------------------------------
ID:7 LABELS:Person PROPS:{name:"张某",born:1967.000000} ID:9 HEAD:7 TAIL:4 TYPE:FRIEND PROPS:{weight:4} ID:12 HEAD:4 TAIL:5 TYPE:FRIEND PROPS:{weight:10} ID:4 HEAD:5 TAIL:2 TYPE:WORK PROPS:{position:"CEO"} ID:2 LABELS:Company PROPS:{name:"百度在线网络技术有限公司",create_at:2000.000000,tagline:"是拥有强大互联网基础的领先AI公司"}
4. 查找关系长度在 2 到 3,并且起始节点是人员"张某"的模式
MATCH (n1:Person{name:"张某"})-[r*2..3]->(n2) RETURN n1,r,n2
结果:
status:OK,cursor:62,result:6,add nodes:0,add links:0,modify nodes:0,modify links:0,delete nodes:0,delete links:0
(1)-----------------------------------------------------------------------
ID:7 LABELS:Person PROPS:{name:"张某",born:1967.000000} ID:10 HEAD:7 TAIL:6 TYPE:FRIEND PROPS:{weight:8} ID:1 HEAD:6 TAIL:0 TYPE:WORK PROPS:{position:"员工"} ID:0 LABELS:Company PROPS:{name:"小米科技有限责任公司",create_at:2010.000000,tagline:"致力于让全球每个人都能享受科技带来的美好生活"}
(2)-----------------------------------------------------------------------
ID:7 LABELS:Person PROPS:{name:"张某",born:1967.000000} ID:9 HEAD:7 TAIL:4 TYPE:FRIEND PROPS:{weight:4} ID:2 HEAD:4 TAIL:1 TYPE:WORK PROPS:{position:"CEO"} ID:1 LABELS:Company PROPS:{name:"阿里巴巴集团控股有限公司",create_at:1999.000000,tagline:"旨在构建未来的商业基础设施"}
(3)-----------------------------------------------------------------------
ID:7 LABELS:Person PROPS:{name:"张某",born:1967.000000} ID:10 HEAD:7 TAIL:6 TYPE:FRIEND PROPS:{weight:8} ID:11 HEAD:6 TAIL:5 TYPE:FRIEND PROPS:{weight:5} ID:4 HEAD:5 TAIL:2 TYPE:WORK PROPS:{position:"CEO"} ID:2 LABELS:Company PROPS:{name:"百度在线网络技术有限公司",create_at:2000.000000,tagline:"是拥有强大互联网基础的领先AI公司"}
(4)-----------------------------------------------------------------------
ID:7 LABELS:Person PROPS:{name:"张某",born:1967.000000} ID:9 HEAD:7 TAIL:4 TYPE:FRIEND PROPS:{weight:4} ID:12 HEAD:4 TAIL:5 TYPE:FRIEND PROPS:{weight:10} ID:4 HEAD:5 TAIL:2 TYPE:WORK PROPS:{position:"CEO"} ID:2 LABELS:Company PROPS:{name:"百度在线网络技术有限公司",create_at:2000.000000,tagline:"是拥有强大互联网基础的领先AI公司"}
(5)-----------------------------------------------------------------------
ID:7 LABELS:Person PROPS:{name:"张某",born:1967.000000} ID:10 HEAD:7 TAIL:6 TYPE:FRIEND PROPS:{weight:8} ID:11 HEAD:6 TAIL:5 TYPE:FRIEND PROPS:{weight:5} ID:5 LABELS:Person PROPS:{name:"李某",born:1968.000000}
(6)-----------------------------------------------------------------------
ID:7 LABELS:Person PROPS:{name:"张某",born:1967.000000} ID:9 HEAD:7 TAIL:4 TYPE:FRIEND PROPS:{weight:4} ID:12 HEAD:4 TAIL:5 TYPE:FRIEND PROPS:{weight:10} ID:5 LABELS:Person PROPS:{name:"李某",born:1968.000000}
5. 全部路径查询
查询两个节点间的所有路径,此操作往往返回的是数据库中所有节点关系的笛卡尔乘积基本的数据量,所以很容易因数据量过大而无法返回,请读者谨慎使用。
MATCH (n1:Person{name:"张某"})-[*]->(n2:Person{name:"王某"}) RETURN n1,r,n2
结果集过大这里不展示。
# 最优路径查询
最优路径可以查最短路径也可以查最长路径,可以是按权值查找也可以按路径长度查找,我们只需在模式中关系描述的 * 后面加上小于号或大于号来代表是最短路径查找还是最长路径查找。
1. 查询"张某"与"赵某"的最短人脉路径
注意我们没有加箭头指向限定。通过下面结果可知张某与马某是朋友,而马某与赵某是同一个公司的同事。
MATCH path=(start :Person{name:"张某"})-[rels *<]- (end :Person{name:"赵某"}) RETURN path
结果:
status:OK,cursor:95,result:1,add nodes:0,add links:0,modify nodes:0,modify links:0,delete nodes:0,delete links:0
(1)-----------------------------------------------------------------------
ID:7 LABELS:Person PROPS:{name:"张某",born:1967.000000} ID:9 HEAD:7 TAIL:4 TYPE:FRIEND PROPS:{weight:4} ID:4 LABELS:Person PROPS:{name:"马某",born:1964.000000} ID:2 HEAD:4 TAIL:1 TYPE:WORK PROPS:{position:"CEO"} ID:1 LABELS:Company PROPS:{name:"阿里巴巴集团控股有限公司",create_at:1999.000000,tagline:"旨在构建未来的商业基础设施"} ID:3 HEAD:9 TAIL:1 TYPE:WORK PROPS:{position:"员工"} ID:9 LABELS:Person PROPS:{name:"赵某",born:1952.000000}
可视化:
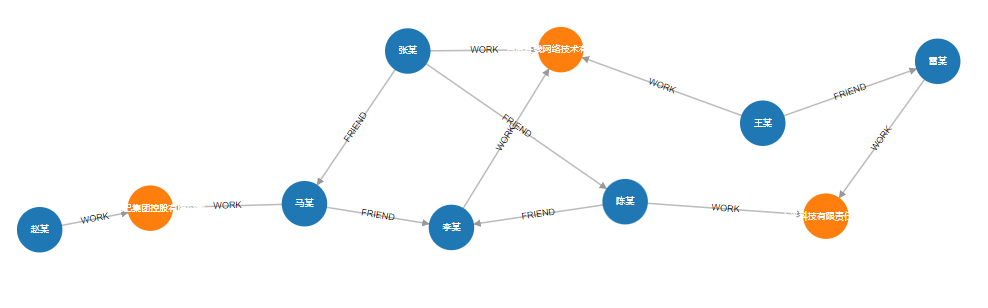
2. 查询"张某"与"赵某"的最长人脉路径
MATCH path=(start :Person{name:"张某"})-[rels *>]- (end :Person{name:"赵某"}) RETURN path
结果数据过多暂不展示。
可视化:
3. 按权重查找最短/最长路径
把路径中关系上的某个属性(应为数值型属性)作为权重累加得到整条路径的权重,以此来查找权重最小或最大的路径。
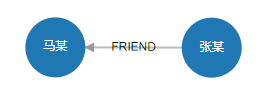
查找马某与张某 weight 权重的最短路径:
MATCH path=(start :Person{name:"马某"})-[ *<weight]- (end :Person{name:"张某"}) RETURN path
结果:
status:OK,cursor:97,result:1,add nodes:0,add links:0,modify nodes:0,modify links:0,delete nodes:0,delete links:0
(1)-----------------------------------------------------------------------
ID:4 LABELS:Person PROPS:{name:"马某",born:1964.000000} ID:9 HEAD:7 TAIL:4 TYPE:FRIEND PROPS:{weight:4.000000} ID:7 LABELS:Person PROPS:{name:"张某",born:1967.000000}
可视化:
查找马某与张某 weight 权重的最长路径:
MATCH path=(start :Person{name:"马某"})-[ *>weight]- (end :Person{name:"张某"}) RETURN path
结果:
status:OK,cursor:97,result:1,add nodes:0,add links:0,modify nodes:0,modify links:0,delete nodes:0,delete links:0
(1)-----------------------------------------------------------------------
ID:4 LABELS:Person PROPS:{name:"马某",born:1964.000000} ID:12 HEAD:4 TAIL:5 TYPE:FRIEND PROPS:{weight:10.000000} ID:5 LABELS:Person PROPS:{name:"李某",born:1968.000000} ID:11 HEAD:6 TAIL:5 TYPE:FRIEND PROPS:{weight:5.000000} ID:6 LABELS:Person PROPS:{name:"陈某",born:1960.000000} ID:10 HEAD:7 TAIL:6 TYPE:FRIEND PROPS:{weight:8.000000} ID:7 LABELS:Person PROPS:{name:"张某",born:1967.000000}
可视化:

# RETURN 指令
RETURN 指令可以按照变量名返回模式匹配到的结果,并在每条结果记录中按变量在 RETURN 后面的出现次序排序,不在 RETURN 后面的变量列表中的变量将不返回。上面语句实例中我们已经大量使用了 RETURN,在这里就不再赘述。
实例:
MATCH (n1)-[r1]->(n2)-[r2]->(n3) RETURN n1,r1,n2,r2,n3
结果:
status:OK,cursor:54,result:8,add nodes:0,add links:0,modify nodes:0,modify links:0,delete nodes:0,delete links:0
(1)-----------------------------------------------------------------------
ID:4 LABELS:Person PROPS:{name:"马某",born:1964.000000} ID:12 HEAD:4 TAIL:5 TYPE:FRIEND PROPS:{weight:10} ID:5 LABELS:Person PROPS:{name:"李某",born:1968.000000} ID:4 HEAD:5 TAIL:2 TYPE:WORK PROPS:{position:"CEO"} ID:2 LABELS:Company PROPS:{name:"百度在线网络技术有限公司",create_at:2000.000000,tagline:"是拥有强大互联网基础的领先AI公司"}
(2)-----------------------------------------------------------------------
ID:6 LABELS:Person PROPS:{name:"陈某",born:1960.000000} ID:11 HEAD:6 TAIL:5 TYPE:FRIEND PROPS:{weight:5} ID:5 LABELS:Person PROPS:{name:"李某",born:1968.000000} ID:4 HEAD:5 TAIL:2 TYPE:WORK PROPS:{position:"CEO"} ID:2 LABELS:Company PROPS:{name:"百度在线网络技术有限公司",create_at:2000.000000,tagline:"是拥有强大互联网基础的领先AI公司"}
(3)-----------------------------------------------------------------------
ID:7 LABELS:Person PROPS:{name:"张某",born:1967.000000} ID:10 HEAD:7 TAIL:6 TYPE:FRIEND PROPS:{weight:8} ID:6 LABELS:Person PROPS:{name:"陈某",born:1960.000000} ID:11 HEAD:6 TAIL:5 TYPE:FRIEND PROPS:{weight:5} ID:5 LABELS:Person PROPS:{name:"李某",born:1968.000000}
(4)-----------------------------------------------------------------------
ID:7 LABELS:Person PROPS:{name:"张某",born:1967.000000} ID:10 HEAD:7 TAIL:6 TYPE:FRIEND PROPS:{weight:8} ID:6 LABELS:Person PROPS:{name:"陈某",born:1960.000000} ID:1 HEAD:6 TAIL:0 TYPE:WORK PROPS:{position:"员工"} ID:0 LABELS:Company PROPS:{name:"小米科技有限责任公司",create_at:2010.000000,tagline:"致力于让全球每个人都能享受科技带来的美好生活"}
(5)-----------------------------------------------------------------------
ID:7 LABELS:Person PROPS:{name:"张某",born:1967.000000} ID:9 HEAD:7 TAIL:4 TYPE:FRIEND PROPS:{weight:4} ID:4 LABELS:Person PROPS:{name:"马某",born:1964.000000} ID:12 HEAD:4 TAIL:5 TYPE:FRIEND PROPS:{weight:10} ID:5 LABELS:Person PROPS:{name:"李某",born:1968.000000}
(6)-----------------------------------------------------------------------
ID:7 LABELS:Person PROPS:{name:"张某",born:1967.000000} ID:9 HEAD:7 TAIL:4 TYPE:FRIEND PROPS:{weight:4} ID:4 LABELS:Person PROPS:{name:"马某",born:1964.000000} ID:2 HEAD:4 TAIL:1 TYPE:WORK PROPS:{position:"CEO"} ID:1 LABELS:Company PROPS:{name:"阿里巴巴集团控股有限公司",create_at:1999.000000,tagline:"旨在构建未来的商业基础设施"}
(7)-----------------------------------------------------------------------
ID:8 LABELS:Person PROPS:{name:"王某",born:1965.000000} ID:7 HEAD:8 TAIL:3 TYPE:FRIEND PROPS:{weight:2} ID:3 LABELS:Person PROPS:{name:"雷某",born:1969.000000} ID:0 HEAD:3 TAIL:0 TYPE:WORK PROPS:{position:"CEO"} ID:0 LABELS:Company PROPS:{name:"小米科技有限责任公司",create_at:2010.000000,tagline:"致力于让全球每个人都能享受科技带来的美好生活"}
(8)-----------------------------------------------------------------------
ID:9 LABELS:Person PROPS:{name:"赵某",born:1952.000000} ID:8 HEAD:9 TAIL:3 TYPE:FRIEND PROPS:{} ID:3 LABELS:Person PROPS:{name:"雷某",born:1969.000000} ID:0 HEAD:3 TAIL:0 TYPE:WORK PROPS:{position:"CEO"} ID:0 LABELS:Company PROPS:{name:"小米科技有限责任公司",create_at:2010.000000,tagline:"致力于让全球每个人都能享受科技带来的美好生活"}
# WHERE 指令
WHERE 指令必须加载 MATCH 指令后面 RETURN 指令之前,用于条件过滤。
1. 单条件查询
如查询 1965 年后出生的人员:
MATCH (n:Person) WHERE n.born > 1965 RETURN n
结果:
status:OK,cursor:45,result:3,add nodes:0,add links:0,modify nodes:0,modify links:0,delete nodes:0,delete links:0
(1)-----------------------------------------------------------------------
ID:3 LABELS:Person PROPS:{name:"雷某",born:1969.000000}
(2)-----------------------------------------------------------------------
ID:5 LABELS:Person PROPS:{name:"李某",born:1968.000000}
(3)-----------------------------------------------------------------------
ID:7 LABELS:Person PROPS:{name:"张某",born:1967.000000}
2. 多条件组合查询
查询 1965 年后出生并且名字以"李"开头的人员:
MATCH (n:Person) WHERE n.born > 1965 AND n.name =~ "李*" RETURN n
结果:
status:OK,cursor:66,result:1,add nodes:0,add links:0,modify nodes:0,modify links:0,delete nodes:0,delete links:0
(1)-----------------------------------------------------------------------
ID:5 LABELS:Person PROPS:{name:"李某",born:1968.000000}
3. 模式匹配
* 匹配任意多个字符,_ 匹配单个字符,\ 转义字符。
匹配李开头的人员,用 * 做模式匹配:
MATCH (n:Person) WHERE n.name =~ "李*" RETURN n
结果:
status:OK,cursor:66,result:1,add nodes:0,add links:0,modify nodes:0,modify links:0,delete nodes:0,delete links:0
(1)-----------------------------------------------------------------------
ID:5 LABELS:Person PROPS:{name:"李某",born:1968.000000}
匹配李开头的人员,用三个 _ 做一个汉字的模式匹配(注意:一个汉字占用三个英文字符空间):
MATCH (n:Person) WHERE n.name =~ "李___" RETURN n
结果:
status:OK,cursor:66,result:1,add nodes:0,add links:0,modify nodes:0,modify links:0,delete nodes:0,delete links:0
(1)-----------------------------------------------------------------------
ID:5 LABELS:Person PROPS:{name:"李某",born:1968.000000}
\ 可以对 * _ \ 进行转义,比如 abc\*d 可以匹配 abc*d,abc\_d 可以匹配 abc_d,abc\\d 可以匹配 abc\d。
# 正则表达式匹配 =~(2.0 增强)
NeuroDB 2.0 全面增强了 =~ 操作符,在原有通配符(* _ \)基础上,增加了标准正则表达式语法的支持。
# 基础通配符(1.0 兼容)
| 符号 | 含义 | 示例 |
|---|---|---|
* | 匹配零个或多个字符 | "李*" 匹配 "李某"、"李某某" |
_ | 匹配单个字符 | "李___" 匹配 "李某"(一个汉字占三个字节) |
\ | 转义字符 | "abc\*d" 匹配字符串 "abc*d" |
# 2.0 新增正则语法
| 符号 | 含义 | 示例 |
|---|---|---|
^ | 匹配字符串开头 | '^John' 以 John 开头 |
$ | 匹配字符串结尾 | 'Smith$' 以 Smith 结尾 |
. | 匹配任意单个字符 | 'J.hn' 匹配 John、Jahn |
* | 零次或多次(正则模式) | 'Jo*hn' 匹配 Jhn、John、Joohn |
+ | 一次或多次 | '\\d+' 匹配一个或多个数字 |
? | 零次或一次 | 'Mr\\.? Smith' 匹配 Mr Smith 或 Mr. Smith |
\d | 匹配数字 | '\\d+' |
\w | 匹配字母数字下划线 | '\\w+' |
\s | 匹配空白字符 | 'a\\sb' |
\b | 单词边界 | '.*\\bJava\\b.*' |
[abc] | 字符类 | '[abc]' 匹配 a、b、c |
[^abc] | 否定字符类 | '[^abc]' |
[a-z] | 字符范围 | '[a-zA-Z]+' |
{n} | 恰好 n 次 | '\\d{6}' |
{n,} | 至少 n 次 | '\\d{3,}' |
{n,m} | n 到 m 次 | '\\d{3,20}' |
(a\|b) | 选择分支 | '(Python\|Java\|Go)' |
注意:在 Cypher 字符串中,反斜杠需要双重转义。\\d 表示数字、\\. 表示字面点号、\\\\ 表示字面反斜杠。
# 常用正则匹配示例
-- 精确匹配
MATCH (p:Person) WHERE p.name =~ 'John'
-- 大小写敏感
MATCH (p:Person) WHERE p.name =~ 'JOHN' -- 不匹配 'john'
-- 完全匹配(以 John 开头以 Smith 结尾)
MATCH (p:Person) WHERE p.name =~ '^John Smith$'
-- 包含关键词
MATCH (p:Post) WHERE p.content =~ '.*programmer.*'
-- 邮箱格式(简单)
MATCH (p:Person) WHERE p.email =~ '^[a-zA-Z0-9]+@[a-zA-Z0-9]+\\.[a-zA-Z]{2,}$'
-- 邮箱格式(完整)
MATCH (p:Person) WHERE p.email =~ '^[a-zA-Z0-9._+-]+@[a-zA-Z0-9.-]+\\.[a-zA-Z]{2,}$'
-- Gmail 地址专用
MATCH (p:Person) WHERE p.email =~ '^[a-zA-Z0-9._%+-]+@gmail\\.com$'
-- 手机号格式(中国)
MATCH (p:Person) WHERE p.phone =~ '^1[3-9]\\d{9}$'
-- 美国电话号码
MATCH (p:Person) WHERE p.phone =~ '^\\d{3}-\\d{3}-\\d{4}$'
-- 身份证号(中国)
MATCH (p:Person) WHERE p.id_card =~ '^\\d{17}[\\dXx]$'
-- 日期格式 YYYY-MM-DD
MATCH (e:Event) WHERE e.date =~ '^\\d{4}-\\d{2}-\\d{2}$'
-- 日期格式 MM/DD/YYYY
MATCH (e:Event) WHERE e.date =~ '^\\d{2}/\\d{2}/\\d{4}$'
-- HTTP/HTTPS URL
MATCH (l:Link) WHERE l.url =~ '^https?://[a-zA-Z0-9.-]+\\.[a-zA-Z]{2,}(/.*)?$'
-- 域名格式
MATCH (w:Website) WHERE w.domain =~ '^[a-zA-Z0-9.-]+\\.[a-zA-Z]{2,}$'
-- IPv4 地址
MATCH (s:Server) WHERE s.ip =~ '^\\d{1,3}\\.\\d{1,3}\\.\\d{1,3}\\.\\d{1,3}$'
-- MAC 地址
MATCH (d:Device) WHERE d.mac =~ '^([0-9A-Fa-f]{2}[:-]){5}([0-9A-Fa-f]{2})$'
-- 整数
MATCH (p:Product) WHERE p.price =~ '^\\d+$'
-- 小数(可选两位小数)
MATCH (p:Product) WHERE p.price =~ '^\\d+(\\.\\d{1,2})?$'
-- 语义化版本号
MATCH (s:Software) WHERE s.version =~ '^\\d+\\.\\d+\\.\\d+$'
-- 带预发布标识的版本号
MATCH (s:Software) WHERE s.version =~ '^\\d+\\.\\d+\\.\\d+(-[a-zA-Z0-9]+)?$'
-- 用户名格式(字母数字下划线,3-20 位)
MATCH (u:User) WHERE u.username =~ '^[a-zA-Z0-9_]{3,20}$'
-- 强密码格式(至少 8 位,包含大小写字母和数字)
MATCH (u:User) WHERE u.password =~ '^(?=.*[a-z])(?=.*[A-Z])(?=.*\\d).{8,}$'
-- 中国邮政编码
MATCH (a:Address) WHERE a.zipcode =~ '^\\d{6}$'
-- 美国邮编(12345 或 12345-6789)
MATCH (a:Address) WHERE a.zipcode =~ '^\\d{5}(-\\d{4})?$'
-- 银行账号验证
MATCH (a:Account) WHERE a.account_number =~ '^\\d{10,20}$'
-- 商品编码(如 AB123456)
MATCH (p:Product) WHERE p.sku =~ '^[A-Z]{2,3}\\d{6}$'
-- 信用卡号(简化版)
MATCH (c:CreditCard) WHERE c.number =~ '^\\d{4}\\s?\\d{4}\\s?\\d{4}\\s?\\d{4}$'
-- HTML 标签检测
MATCH (c:Content) WHERE c.text =~ '.*<[^>]+>.*'
-- 包含 hashtag
MATCH (p:Post) WHERE p.content =~ '.*#[a-zA-Z0-9_]+.*'
-- 包含 @用户名
MATCH (p:Post) WHERE p.content =~ '.*@[a-zA-Z0-9_]+.*'
-- 测试正则表达式
RETURN 'test@example.com' =~ '^[^@]+@[^@]+\\.[a-z]+$' AS is_valid_email
# 复合条件示例
-- 多个正则条件组合
MATCH (p:Person)
WHERE p.name =~ '^J.*'
AND p.email =~ '.*@gmail\\.com$'
AND p.phone =~ '^\\d{3}-\\d{3}-\\d{4}$'
-- 正则与普通条件组合
MATCH (p:Person)
WHERE p.age > 25
AND p.name =~ '^[A-Z][a-z]+\\s[A-Z][a-z]+$'
AND p.status = 'active'
-- OR 条件组合
MATCH (u:User)
WHERE u.email =~ '.*@(gmail|yahoo|hotmail)\\.com$'
OR u.username =~ '^admin.*'
-- 数据质量检查:查找格式不规范的电话
MATCH (p:Person)
WHERE NOT p.phone =~ '^\\d{3}-\\d{3}-\\d{4}$'
AND p.phone IS NOT NULL
-- 查找包含特殊字符的用户名
MATCH (u:User)
WHERE u.username =~ '.*[^a-zA-Z0-9_].*'
# 性能优化建议
- 使用锚点提高性能:尽量使用
^和$锚点限制匹配范围 - 避免贪婪匹配:使用非贪婪匹配
.*?替代.* - 结合索引使用:先用普通条件(如标签、属性值)过滤缩小范围,再用正则匹配
- 避免回溯复杂:在大量数据上避免使用过于复杂的回溯模式
# ORDER BY 指令
对结果集按元素的某个属性进行排序,配合 ASC 与 DESC 指定升序降序,ORDER BY 后也可以添加多个排序项,这将实现按多个排序项依次排序。
MATCH (n:Person) RETURN n ORDER BY n.born ASC
结果:
status:OK,cursor:45,result:7,add nodes:0,add links:0,modify nodes:0,modify links:0,delete nodes:0,delete links:0
(1)-----------------------------------------------------------------------
ID:9 LABELS:Person PROPS:{name:"赵某",born:1952.000000}
(2)-----------------------------------------------------------------------
ID:6 LABELS:Person PROPS:{name:"陈某",born:1960.000000}
(3)-----------------------------------------------------------------------
ID:4 LABELS:Person PROPS:{name:"马某",born:1964.000000}
(4)-----------------------------------------------------------------------
ID:8 LABELS:Person PROPS:{name:"王某",born:1965.000000}
(5)-----------------------------------------------------------------------
ID:7 LABELS:Person PROPS:{name:"张某",born:1967.000000}
(6)-----------------------------------------------------------------------
ID:5 LABELS:Person PROPS:{name:"李某",born:1968.000000}
(7)-----------------------------------------------------------------------
ID:3 LABELS:Person PROPS:{name:"雷某",born:1969.000000}
# SKIP 指令
SKIP 指令用于跳过结果集中指定个数的记录,只返回后续的。
MATCH (n:Person) RETURN n SKIP 5
结果:
status:OK,cursor:32,result:2,add nodes:0,add links:0,modify nodes:0,modify links:0,delete nodes:0,delete links:0
(1)-----------------------------------------------------------------------
ID:8 LABELS:Person PROPS:{name:"王某",born:1965.000000}
(2)-----------------------------------------------------------------------
ID:9 LABELS:Person PROPS:{name:"赵某",born:1952.000000}
# LIMIT 指令
LIMIT 指令用于限制返回记录的个数,只返回原结果集中从开头开始指定个数的记录。
MATCH (n:Person) RETURN n LIMIT 1
结果:
status:OK,cursor:33,result:1,add nodes:0,add links:0,modify nodes:0,modify links:0,delete nodes:0,delete links:0
(1)-----------------------------------------------------------------------
ID:3 LABELS:Person PROPS:{name:"雷某",born:1969.000000}
利用 SKIP 指令和 LIMIT 指令可以实现分页功能,如每页 3 条记录返回第 3 页:
MATCH (n) RETURN n SKIP 6 LIMIT 3
结果:
status:OK,cursor:33,result:3,add nodes:0,add links:0,modify nodes:0,modify links:0,delete nodes:0,delete links:0
(1)-----------------------------------------------------------------------
ID:6 LABELS:Person PROPS:{name:"陈某",born:1960.000000}
(2)-----------------------------------------------------------------------
ID:7 LABELS:Person PROPS:{name:"张某",born:1967.000000}
(3)-----------------------------------------------------------------------
ID:8 LABELS:Person PROPS:{name:"王某",born:1965.000000}
# CREATE 指令
CREATE 指令用于根据模式表达式创建图数据,图数据也就是节点与关系的集合。模式表达式可以是单个的节点或者节点与关系的组合,但不能是单独的关系,因为不能创建没有首尾节点的"悬空"关系,上面入门实例中我们已经使用过 CREATE 指令。
1. 创建一个独立节点
CREATE (:Person {name:"张三", born:1969})
2. 创建一个关系,并带有首尾节点
CREATE (:Person {name:"张三", born:1969})-[:FRIEND]->(:Person {name:"李四", born:1969})
3. 根据一个略复杂的模式表达式创建节点关系的集合
CREATE (:Person {name:"张三", born:1969})-[:FRIEND]->(:Person {name:"李四", born:1969})-[:WORK]->(:Company {name:"小米科技有限责任公司", create_at:2010})
# MERGE 指令
MERGE 指令用于先根据模式表达式到数据库中像 MATCH 指令那样查找是否有匹配的数据,如果没有则像 CREATE 指令那样创建模式表达的数据,如果有则不做任何处理。
1. 已存在则不做处理
以下指令数据库不做任何处理,因为数据库已经存在模式描述的节点:
MERGE (:Person {name:"雷某", born:1969})
2. 能匹配上的数据不做处理
以下指令数据库依然不做任何处理,因为数据库中存在能匹配上的数据:
MERGE (:Person {name:"赵某", born:1952})-[r:FRIEND]->(:Person {name:"雷某", born:1969})
3. 不存在则创建
以下指令会根据模式新建模式中描述的所有节点和关系,因为没有在数据库中匹配到符合模式的数据:
MERGE (:Person {name:"赵某", born:1952})-[r:LOVE]->(:Person {name:"雷某", born:1969})
上面指令执行完毕后,数据库中会有两个"赵某"节点和两个"雷某"节点,但其中一对赵某雷某之间是用"LOVE"关系连接的。
# DELETE 指令
DELETE 指令必须在 MATCH 指令后,用于删除 MATCH 到的某个数据项,数据项可以是节点也可以说是关系。注意如果要删除一个节点,但此节点还带有关联的关系,则 DELETE 指令会无法删除,因为不能让关系"悬空",需要先删掉关联的关系,然后才能删除此节点。
1. 无法删除示例
下面指令将提示无法删除,因为节点雷某还关联着"WORK"和"FRIEND"关系:
MATCH (n:Person {name:"王某"}) DELETE n
结果:
status:CLIST_HAS_LINK_ERR,cursor:62,result:0,add nodes:0,add links:0,modify nodes:0,modify links:0,delete nodes:0,delete links:0
2. 删除成功示例
先删除王某和雷某之间的 FRIEND 关系:
MATCH (:Person {name:"王某"})-[r:FRIEND]->(:Person {name:"雷某"}) DELETE r
# DETACH DELETE 指令
DETACH DELETE 指令与 DELETE 指令相似必须在 MATCH 指令后,用于删除 MATCH 到的某个数据项,但 DETACH DELETE 指令会先删除所有关联关系然后删除节点,DETACH DELETE 指令可以一次完成这两步操作,因此 DETACH DELETE 指令不会出现无法删除的情况。
MATCH (n:Person {name:"雷某", born:1969}) DETACH DELETE n
结果:
status:OK,cursor:69,result:0,add nodes:0,add links:0,modify nodes:0,modify links:0,delete nodes:1,delete links:0
# SET 指令
SET 指令必须在 MATCH 指令后,用于为节点或关系设置属性,如果已经有同名属性了,则 SET 会覆盖原来的属性值,否则就新建此属性。
1. 为人员"张某"添加性别属性
MATCH (n :Person{name:"张某"}) SET n.sex="男" RETURN n
2. 为人员"张某"修改性别属性为女
MATCH (n :Person{name:"张某"}) SET n.sex="女" RETURN n
3. 为人员"张某"修改 Person 标签为 Person2
MATCH (n :Person{name:"张某"}) SET n:Person2 RETURN n
# REMOVE 指令
REMOVE 指令必须在 MATCH 指令后,用于移除节点或关系上的属性。
1. 移除属性
MATCH (n :Person{name:"张某"}) REMOVE n.sex RETURN n
2. 移除标签
MATCH (n :Person{name:"张某"}) REMOVE n:Person RETURN n
# CALL 指令
CALL 指令用于调用系统内的存储过程,每个存储过程都有自己的功能。
1. db.labels() 返回数据库内所有的节点标签
CALL db.labels()
结果:
status:OK,cursor:16,result:2,add nodes:0,add links:0,modify nodes:0,modify links:0,delete nodes:0,delete links:0
(1)-----------------------------------------------------------------------
"Person"
(2)-----------------------------------------------------------------------
"Company"
2. db.types() 返回数据库内所有的关系类型
CALL db.types()
结果:
status:OK,cursor:15,result:2,add nodes:0,add links:0,modify nodes:0,modify links:0,delete nodes:0,delete links:0
(1)-----------------------------------------------------------------------
"FRIEND"
(2)-----------------------------------------------------------------------
"WORK"
3. result.count() 返回结果集个数
MATCH (n) CALL result.count()
结果:
status:OK,cursor:29,result:1,add nodes:0,add links:0,modify nodes:0,modify links:0,delete nodes:0,delete links:0
(1)-----------------------------------------------------------------------
10.000000
4. db.nodeLinkCount() 返回数据库中当前节点总个数和关系边总个数
CALL db.nodeLinkCount()
结果:
status:OK,cursor:29,result:1,add nodes:0,add links:0,modify nodes:0,modify links:0,delete nodes:0,delete links:0
(1)-----------------------------------------------------------------------
10.000000 13.000000
# LOAD CSV 指令
LOAD CSV 指令用于批量从 CSV 文件导入图数据,数据源必须是 UTF-8 格式的 .csv 文件,我们可以将 CSV 文件放到数据库根目录的"import"文件夹下,这样我们在运行 LOAD CSV 指令时无需写冗长的文件路径,只写文件名即可;不放到"import"文件夹则需要在指令中给出 CSV 文件全路径。
1. 配合 CREATE 指令,从 "test.csv" 读取所有行,并把每行第一列作为"name"属性批量导入并创建"Person"节点
LOAD CSV FROM "test.csv" AS line CREATE (:Person{name:line[1]})
2. 上面例子也可以换成 MERGE 指令
LOAD CSV FROM "test.csv" AS line MERGE (:Person{name:line[2]})
3. 也可以同时导入创建节点标签、关系类型和属性
LOAD CSV FROM "test.csv" AS line CREATE (:line[0]{line[1]:line[2]})
4. 对于带有"表头(标题)"的 CSV 文件,可以用 LOAD CSV WITH HEADERS 指令
文件名后要加上 AS line 作为每行的变量名,这里"line"就是变量名,可以自己任意定义其他名字。
LOAD CSV WITH HEADERS FROM "test.csv" AS line CREATE (:line.label{name:line.name, age:line.age})
5. 也可以配合 MATCH 指令,从数据库中整合已有数据来创建新的图数据
LOAD CSV FROM "test.csv" AS line MATCH (n:Person{name:line[2]}) CREATE (n)-[:line[4]{size:line[3]}]->(:Job{name:line[5]})
# 快速导入(2.0 新增)
NeuroDB 2.0 新增了高效的批量导入命令,无需逐行解析 Cypher 语句,直接批量构建节点和关系,导入效率远高于常规 LOAD CSV 方式:
-- 快速导入节点
LOAD CSV FROM "node.csv" NODES
-- 快速导入关系边
LOAD CSV FROM "relationship.csv" RELATIONSHIPS
node.csv 应包含节点字段(如 id、label、属性名和属性值),relationship.csv 应包含关系字段(如起始节点 id、结束节点 id、类型、属性等)。具体 CSV 格式请参考 import/ 目录下的示例文件。
# 主从复制集群(2.0 新增)
NeuroDB 2.0 采用 C 语言实现了完整的主从复制功能,支持一主多从架构,实现数据高可用与读写分离。
# 架构概览
┌─────────────┐
│ Master │
│ (主节点) │
│ 读写均可 │
└──┬───┬───┬──┘
│ │ │
SYNC/增量 │ │ │
命令传播 │ │ │
┌───────────┘ │ └───────────┐
│ │ │
▼ ▼ ▼
┌──────┐ ┌──────┐ ┌──────┐
│Slave1│ │Slave2│ │Slave3│
│(从节点)│ │(从节点)│ │(从节点)│
│ 只读 │ │ 只读 │ │ 只读 │
└──────┘ └──────┘ └──────┘
# 核心机制
NeuroDB 主从复制采用全量同步 + 增量命令传播的方式,由状态机驱动整个同步流程。
# 1. 全量同步(RDB 方式)
从节点首次连接主节点时,主节点通过 fork() 创建子进程执行 BGSAVE(后台保存),生成 RDB 快照文件发送给从节点。fork() 利用操作系统的写时复制(Copy-on-Write)机制,主进程不阻塞,继续正常服务客户端请求。
# 2. BGSAVE 复用
如果多个从节点同时请求同步,且已有 BGSAVE 进程在运行,后续的从节点会复用同一个 BGSAVE 结果,避免重复磁盘 I/O。主节点会复制已有从节点的 reply 缓冲区,确保在 BGSAVE 期间执行的写命令能传播给后来加入的从节点。
# 3. 增量同步(命令传播)
全量同步完成后,从节点进入在线状态(REDIS_REPL_ONLINE)。此后主节点每执行一次写命令(CREATE、DELETE、SET、REMOVE 等),都会通过 replicationFeedSlaves() 将命令以 Redis 协议格式(*<argc>\r\n$<len>\r\n<data>\r\n 格式)传播给所有在线的从节点。
# 4. 心跳与超时检测
- 主节点定期(默认每 10 秒)向在线从节点发送 PING 心跳
- 从节点在接收 RDB 文件时检测传输超时,超时后自动中断同步
- 从节点在在线状态下检测主节点连接超时,超时后释放主节点连接
# 使用方法
# 启动主节点
./NEURO_SERVER
# 默认监听 8839 端口
主节点无需特殊配置,启动后即可接受从节点的同步请求。
# 配置从节点
先启动从节点的 NEURO_SERVER 服务,然后通过 NEURO_CLI 连接从节点执行:
SLAVEOF <master_host> <master_port>
例如:
SLAVEOF 192.168.1.100 8839
执行后,从节点将自动完成以下完整流程:
- 连接阶段:建立到主节点的 TCP 连接,发送 AUTH(如配置了密码)和 SYNC 命令
- 传输阶段:创建临时文件
temp-<time>.<pid>.rdb,接收主节点发来的 RDB 全量数据 - 加载阶段:数据接收完毕后,原子性
rename()为正式文件,清空当前数据库,加载 RDB 文件 - 在线阶段:进入 REPL_CONNECTED 状态,持续接收主节点推送的增量写命令
# 取消复制
SLAVEOF NO ONE
执行后,节点恢复为独立节点,释放与主节点的连接,不再接收同步数据。原有的本地数据不会丢失。
# 完整同步流程
# 从节点状态流转
SLAVEOF <host> <port>
│
▼
REPL_CONNECT ← syncWithMaster() 建立连接、发送 SYNC
│
▼
REPL_TRANSFER ← readSyncBulkPayload() 接收 RDB 文件
│
▼
REPL_CONNECTED ← 进入在线状态,接收增量命令
# 主节点对从节点的处理流程
收到 SYNC 命令
│
┌────┴────┐
│ │
已有 BGSAVE 无 BGSAVE
│ │
├─有从节点等待─┐ │
│ 复用结果 │ ▼
│ │ 启动 BGSAVE
▼ ▼ │
WAIT_BGSAVE WAIT_BGSAVE │
_END _START │
│ │ │
└────┬────┘ │
▼ ▼
BGSAVE 完成 ← ──┘
│
▼
REPL_SEND_BULK ← sendBulkToSlave() 分块发送 RDB
│
▼
REPL_ONLINE ← 发送增量命令
# 注意事项
- 主从复制功能当前主要支持 Linux 平台,Windows 版本需要类似的适配
- 采用 RDB 方式进行全量+增量同步,AOF(Append Only File)功能尚未实现
- 建议主从节点间网络延迟较低,以保证增量同步的实时性
- 从节点默认为只读,不直接接受写操作
- 如需持久化,建议在主节点上配置合适的
save-strategy
# 运维管理
# SAVEDB 指令
因为 NeuroDB 是内存级图数据库,所以所有的数据都是在内存中操作的,如果想把数据持久化保存在磁盘上形成文件,文件是 /data/neuro.ndb,这样下次启动 NeuroDB 时会自动恢复数据。因此建议在更改数据后或者关闭 NeuroDB 前运行 SAVEDB 指令。
注意,NeuroDB 在配置文件 neuro.conf 中如果配置的存储策略(save-strategy)为 1(数据变动后自动保存),则无需手动执行 SAVEDB 命令,系统会在数据发生变化后自己动执行。
如果用户想要定期备份数据库,可以利用操作系统的定时任务将 neuro.ndb 定期复制备份到他处即可。
如果删除 neuro.ndb 将导致数据被全部清空。
SAVEDB
# CREATE DATABASE 指令
NeuroDB 支持创建多个图数据库,默认启动 NeuroDB 会有一个名叫"default"的数据库提供给用户,如果想要新建一个数据库则用 CREATE DATABASE 指令,后面加上数据库命名即可。
CREATE DATABASE mydatabase
# SHOW DATABASES 指令
想要查看系统中有哪些数据库,则使用 SHOW DATABASES 指令。
SHOW DATABASES
结果:
INFO:
default
mydatabase
# USE 指令
USE 指令加上数据库名,可以切换到指定数据库,后面所有操作将在此数据库上进行。
USE mydatabase
# DROP DATABASE 指令
DROP DATABASE 指令加上数据库名,可以删除指定数据库,为了数据安全请谨慎操作。
DROP DATABASE mydatabase
# SHUTDOWN 指令
SHUTDOWN 指令用于关闭服务端服务进程,在关闭前会自动执行持久化存储操作。
SHUTDOWN
# 服务配置文件
在 NeuroDB 根目录的 bin 目录下有 neuro.conf 文件,其中包含了系统的一些配置信息,并且每行配置信息都有注释,用户可以根据需求自行配置。
# 服务启动的端口号
port 8839
# 客户端超时注销时间(秒)
max-idletime 300
# 持久化策略 0 执行存盘命令时(默认),1 数据变动时,2 关闭数据库时 3 空闲时(无客户端连接时) 4 大于4时,定时间隔时间,单位秒
save-strategy 1
# 日志级别,取值范围为:0-5,关闭级别:OFF_LEVEL 0, 错误级别:ERROR_LEVEL 1 ,警告级别:ARNING_LEVEL 2,正常消息级别:INFO_LEVEL 3, 调试级别: DEBUG_LEVEL 4, 全部打印日志级别:CMD_lEVEL 5,高级别会同时打印低级别的日志
log-level 4
# 查询超时中断时间(秒)
query-timeout 5
# 客户端启动参数
NEURO_CLI 客户端默认链接 IP 为 127.0.0.1(本机)的 8839 端口,也就是 NEURO_SERVER 服务的默认启动端口,如果用户想要修改可以使用 ip 与 port 参数。
如要连接 IP 为 192.168.0.1 服务器上的启动端口为 8888 的 NEURO_SERVER 服务:
Windows 系统:
NEURO_CLI.exe ip 192.168.0.1 port 8888
Linux 系统:
./NEURO_CLI ip 192.168.0.1 port 8888
# 运行日志
在 NeuroDB 根目录的 logs 目录下有 neuro.log 文件,其中记录了所有运行事件、命令执行记录,我们可以根据日志查看运行记录和恢复数据,因为日志中已经按顺序记录了所有执行过的命令,所以我们依次执行完相应命令就可以恢复数据。
neuro.log 内容如下:
[2025-03-23 09:43:11][INFO] Server start at localhost:8839
[2025-03-23 09:43:11][INFO] DB loaded from disk
[2025-03-23 09:49:34][INFO] Server start at localhost:8839
[2025-03-23 09:49:34][INFO] DB loaded from disk
[2025-03-23 09:49:35][DEBUG] 0 clients connected , 9371 bytes in use
[2025-03-23 09:49:40][DEBUG] 0 clients connected , 9371 bytes in use
[2025-03-23 09:49:45][DEBUG] 0 clients connected , 9371 bytes in use
[2025-03-23 09:49:50][DEBUG] 0 clients connected , 9371 bytes in use
[2025-03-23 09:49:51][WARNING] Opening TCP port: bind: No such file or directory
[2025-03-23 09:49:55][DEBUG] 0 clients connected , 9371 bytes in use
[2025-03-23 09:50:00][DEBUG] 0 clients connected , 9371 bytes in use
[2025-03-23 09:50:02][INFO] Accepted 127.0.0.1:49765
[2025-03-23 09:50:02][DEBUG] MATCH (n)-[r]->(m) RETURN n,r,m limit 20
[2025-03-23 09:50:05][DEBUG] 1 clients connected , 11198 bytes in use
[2025-03-23 09:50:10][DEBUG] 1 clients connected , 11198 bytes in use
# 各开发语言驱动
# JavaScript 驱动
JavaScript 驱动下载地址 (opens new window)
代码示例:
import NeuroDBDriver from './neurodb-driver'; // 引入驱动包
// 事件回调方法
let onOpen = function() {};
let onError = function() {};
let onClose = function() {};
// 创建驱动对象,指向 IP:"127.0.0.1",端口:8839
let neurodbBaseAPI = new NeuroDBDriver('127.0.0.1:8839', onOpen, null, onError, onClose);
// 执行指令并返回结果集
let resultSet = neurodbBaseAPI.executeQuery("CREATE (n:Person{name:\"test\"}) RETURN n");
// 执行指令
resultSet = neurodbBaseAPI.executeQuery("MATCH (n) RETURN n");
resultSet 结果集对象数据结构见下方 驱动对象结果集 ResultSet 数据结构 章节。
# Java 驱动
Java 驱动下载地址 (opens new window)
代码示例:
import org.neurodb.NeuroDBDriver; // 引入驱动类
class Test {
public static void main(String[] args) {
try {
// 创建驱动对象,指向 IP:"127.0.0.1",端口:8839
NeuroDBDriver neuroDBDriver = new NeuroDBDriver("127.0.0.1", 8839);
// 执行指令,并得到结果集对象 ResultSet
ResultSet resultSet = neuroDBDriver.executeQuery("CREATE (n:Person{name:\"test\"}) RETURN n");
// 执行指令实例 2
resultSet = neuroDBDriver.executeQuery("MATCH (n) RETURN n");
// 后期不再使用则最好关闭驱动对象,如果一直要用就不要关闭
neuroDBDriver.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
resultSet 结果集对象数据结构见下方 驱动对象结果集 ResultSet 数据结构 章节。
# Python 驱动
Python 驱动下载地址 (opens new window)
代码示例:
import NeuroDBDriver # 引入驱动模块
# 创建驱动对象,指向 IP:"127.0.0.1",端口:8839
driver = NeuroDBDriver("127.0.0.1", 8839)
# 执行指令,并得到结果集对象 ResultSet
resultSet = driver.executeQuery("CREATE (n:Person{name:\"test\"}) RETURN n")
# 执行指令实例 2
resultSet = driver.executeQuery("MATCH (n) RETURN n")
resultSet 结果集对象数据结构见下方 驱动对象结果集 ResultSet 数据结构 章节。
# .NET 驱动
.NET 驱动下载地址 (opens new window)
代码示例:
using System;
using NeuroDB_DotNet_Driver; // 引入驱动类
namespace Test
{
class Program
{
static void Main(string[] args)
{
// 创建驱动对象,指向 IP:"127.0.0.1",端口:8839
NeuroDBDriver driver = new NeuroDBDriver("127.0.0.1", 8839);
// 执行指令,并得到结果集对象 ResultSet
ResultSet resultSet = driver.executeQuery("CREATE (n:Person{name:\"test\"}) RETURN n");
// 执行指令实例 2
resultSet = driver.executeQuery("MATCH (n) RETURN n");
// 后期不再使用则最好关闭驱动对象,如果一直要用就不要关闭
driver.close();
}
}
}
resultSet 结果集对象数据结构见下方 驱动对象结果集 ResultSet 数据结构 章节。
# Go 驱动
Go 驱动下载地址 (opens new window),由社区贡献者 WZFlik (opens new window) 提供。
代码示例:
package tests
import (
"fmt"
"neurodb.org/neurodb"
"testing"
)
func TestDriver(t *testing.T) {
db, err := neurodb.Open("127.0.0.1", 8839)
if err != nil {
t.Error(err)
}
resultSet, err := db.ExecuteQuery("MATCH (n) RETURN n")
if err != nil {
t.Error(err)
}
for resultSet.Next() {
fmt.Println(resultSet.Record())
}
resultSet, err = db.ExecuteQuery("MATCH (n)-[r]->(m) RETURN n,r,m")
if err != nil {
t.Error(err)
}
for resultSet.Next() {
fmt.Println(resultSet.Record())
}
}
resultSet 结果集对象数据结构见下方 驱动对象结果集 ResultSet 数据结构 章节。
# Dart 驱动
Dart 驱动下载地址 (opens new window),由社区贡献者 dudu-ltd (opens new window) 提供。
代码示例:
import 'package:neurodb_dart_driver/neurodb_dart_driver.dart';
void main() async {
var driver = NeuroDBDriver("127.0.0.1", 8839);
ResultSet resultSet = await driver.executeQuery("MATCH (n) RETURN n");
resultSet = await driver.executeQuery("MATCH (n)-[r]->(m) RETURN n,r,m");
print("ok");
driver.close();
}
resultSet 结果集对象数据结构见下方 驱动对象结果集 ResultSet 数据结构 章节。
# 驱动对象结果集 ResultSet 数据结构
# ResultSet 返回结果数据结构
| 字段 | 类型 | 说明 |
|---|---|---|
cursor | int | 指令解析指针(如果有语法错误则指针索引不指向最后一个字符) |
status | string | 状态,"OK" 为成功返回,否则提示 ERROR 信息 |
msg | string | 附属信息(如"运行成功") |
results | int | 结果集中结果记录的个数 |
addNodes | int | 添加节点个数 |
addLinks | int | 添加关系边个数 |
modifyNodes | int | 修改节点个数 |
modifyLinks | int | 修改关系边个数 |
deleteNodes | int | 删除节点个数 |
deleteLinks | int | 删除关系边个数 |
recordSet | object | 结果集 |
# recordSet 结果集内数据结构
| 字段 | 说明 |
|---|---|
labels | 结果集中所有节点的 label 标签集合 |
types | 结果集中所有关系边的 type 类型集合 |
keyNames | 结果集中所有节点、关系边的属性名集合 |
nodes | 结果集内所有节点 |
links | 结果集内所有关系边 |
records | 结果集按 Return 指令后变量排列顺序排列的节点、关系边、路径组成的结果记录列表 |
# node 节点数据结构
| 字段 | 说明 |
|---|---|
id | 节点 ID |
labels | 节点标签数组 |
properties | 属性列表,每个属性包含属性名、属性值 |
# link 关系边数据结构
| 字段 | 说明 |
|---|---|
id | 关系边 ID |
hid | 头节点 ID |
tid | 尾节点 ID |
type | 关系边类型 |
properties | 属性列表,每个属性包含属性名、属性值 |
# ResultSet 实例(以 JSON 展示)
{
"cursor": 39,
"status": "OK",
"msg": "运行成功",
"results": 1,
"addNodes": 0,
"addLinks": 0,
"modifyNodes": 0,
"modifyLinks": 0,
"deleteNodes": 0,
"deleteLinks": 0,
"recordSet": {
"nodes": [
{
"id": 19,
"labels": ["staff"],
"properties": {
"name": "张三",
"sex": "男"
}
},
{
"id": 959,
"labels": ["company"],
"properties": {
"name": "XX科技公司"
}
}
],
"links": [
{
"id": 1216,
"hid": 19,
"tid": 959,
"type": "WORK_FOR",
"properties": {}
}
],
"records": [
[
{
"id": 19,
"labels": ["staff"],
"properties": {
"name": "张三",
"sex": "男"
}
},
{
"id": 1216,
"hid": 19,
"tid": 959,
"type": "WORK_FOR",
"properties": {}
},
{
"id": 959,
"labels": ["company"],
"properties": {
"name": "XX科技公司"
}
}
]
],
"labels": ["staff", "company"],
"types": ["WORK_FOR"],
"keyNames": ["name", "sex"]
}
}
# 内嵌式数据库软件包
NeuroDB 类似 SQLite,可作为嵌入式数据库直接集成到以下语言的项目中:
- C/C++ — 直接链接
libneurodb.a静态库 - JavaScript / Java / Python / C# / Go / Dart — 通过各语言驱动包
# 附录:1.0 → 2.0 迁移说明
# 兼容性
NeuroDB 2.0 保持向后兼容:
- Cypher 查询语法 完全兼容,1.0 的所有查询语句无需修改即可在 2.0 中运行
- 客户端 API 接口保持不变,各语言驱动无缝升级
- RDB 数据文件格式兼容,1.0 的
neuro.ndb可在 2.0 中直接加载 - 配置文件
neuro.conf格式一致
# 主要变更对照
| 方面 | 1.0 | 2.0 |
|---|---|---|
| 解析器 | 手写解析器 | Flex/Bison 工业级解析器 |
| 解析速度 | 基准 | 2-3 倍提升 |
| 错误定位 | 模糊(大致位置) | 精确到字符位置 |
| 错误消息 | 简单 | 详细、准确 |
| 正则表达式 | 仅通配符 * _ \ | 完整正则语法(^ $ + ? \d \w [] {} () 等) |
| 主从复制 | 不支持 | 支持一主多从,全量+增量同步 |
| CSV 导入 | LOAD CSV ... AS line CREATE/MERGE | 新增 LOAD CSV ... NODES / LOAD CSV ... RELATIONSHIPS 快速导入 |
| 代码维护性 | 基准 | 5 倍提升 |
| 语法扩展性 | 基准 | 10 倍提升 |
| 可执行文件 | NEURO_SERVER | NEURO_SERVER(Flex/Bison 新版) |
# 新增依赖
- Flex >= 2.5(词法分析器生成工具)
- Bison >= 3.0(语法分析器生成工具)
用户运行已编译的程序包时无需安装这些依赖,仅在从源码编译时需要。